Data Engineering for Beginners – The Power of Cache

In this post, we will go more in-depth into various concepts related to cache memory and how it impacts processing.
Topic Overview
- The Principle of Locality
- Generic Cache Memory Organization
- Hit/Miss Rate
- Memory Mapping Techniques
- Replacement Algorithms
- Sequential vs. Random Access
- Read-Write Policy
- Impact of Cache on Performance
- Importance of Understanding Locality in Coding
- How to Write Cache-Friendly Code?
The Principle of Locality
Locality of reference is a principle in computer science that refers to the tendency of a computer program to access a small, localized portion of memory repeatedly, rather than accessing large, distant portions of memory infrequently.
This principle is based on the observation that programs often exhibit spatial and temporal locality, which means that they tend to access data that is stored close to data that has been recently accessed, and that they often access the same data repeatedly over time.
Locality of reference is important because it can have a significant impact on the performance of computer programs. If a program can take advantage of the fact that it frequently accesses a small portion of memory, it can optimize its memory usage and improve its performance.
For example, by storing frequently accessed data in a cache that is located close to the CPU, a program can reduce the amount of time it takes to access that data, and improve its overall performance.
There are two main types of locality of reference: spatial locality and temporal locality.
Spatial Locality
Spatial locality refers to the tendency of a program to access data that is located close to other data that has recently been accessed.
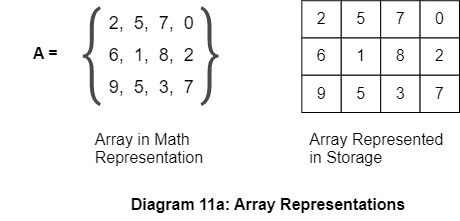
A good example is that of an array. Let’s say A = [20, 21, 30, 31, 40, 41, 50, 51]. Say it is stored as below:
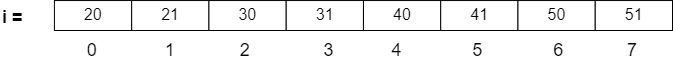
When we try to write a function to access the array and find the sum of elements in it, it goes like this:
sum = 0;
for (i = 0; i < len(A); i++)
sum = sum + A[i]
printf(“Sum of the elements in the array = ”, sum);
We can see here that in every iteration, we want to take the next element of the array. When the array elements are stored in the memory as shown in the above diagram, they are said to be co-located. This helps to access them faster. Thus, this code is said to exhibit spatial locality
Temporal Locality
Temporal locality refers to the tendency of a program to access the same data repeatedly over time.
In the above example, we can see that the variables i and sum are repeatedly being used in every iteration. Thus, if these variables are loaded once, they can be repeatedly accessed quickly until the loop completes. Thus, this code is said to exhibit temporal locality.
Overall, understanding and leveraging the principle of locality of reference is an important part of optimizing the performance of computer programs.
Generic Cache Memory Organization
Cache memory is a small, high-speed memory that is used to store frequently accessed data and instructions that the CPU is likely to need in the near future. A generic cache memory is organized in a hierarchical structure with multiple levels, each with a decreasing size and increasing access speed.
The cache hierarchy generally consists of three levels: L1 cache, L2 cache, and L3 cache.
- The L1 cache is the fastest and smallest level, located within the CPU, and it stores the most frequently accessed data and instructions.
- The L2 cache is larger and slower than the L1 cache, but still faster than the main memory, and is often shared among multiple cores in a multi-core processor.
- The L3 cache, which is the largest and slowest level, is shared among all cores in the processor.
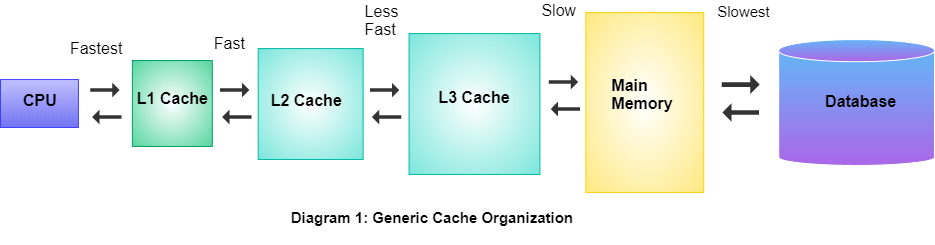
The generic cache memory organization uses a cache controller to manage the flow of data between the CPU and the cache.
- When the CPU needs to access data, the cache controller first checks the L1 cache. If the data is found in the L1 cache, it is returned to the CPU immediately.
- If the data is not found in the L1 cache, the cache controller checks the L2 cache. If the data is found in the L2 cache, it is returned to the CPU.
- If the data is not found in either the L1 or L2 cache, the cache controller checks the L3 cache. If the data is found in the L3 cache, it is returned to the CPU, and if it is not found in any of the cache levels, the cache controller retrieves the data from the main memory.
The generic cache memory organization also uses a cache replacement policy to manage the cache’s limited capacity. The most commonly used replacement policy is Least Recently Used (LRU), which removes the least recently used data from the cache when its capacity is full.
In summary, the generic cache memory organization is designed to minimize the access time to frequently used data, and to minimize the number of accesses to the slower main memory, which can significantly improve the overall performance of the CPU.
Hit/Miss Rate
Hit rate and miss rate are terms used to describe the effectiveness of a cache system in improving memory access times.
Hit rate: It refers to the percentage of memory access requests that can be satisfied from the cache. In other words, when the CPU requests data from memory, and the data is found in the cache, a hit occurs. The hit rate is calculated by dividing the number of cache hits by the total number of memory requests.
Miss rate: It refers to the percentage of memory access requests that cannot be satisfied from the cache and need to be fetched from the main memory. A miss occurs when the CPU requests data from memory, and the data is not found in the cache. The miss rate is calculated by dividing the number of cache misses by the total number of memory requests.
Hit rate and miss rate are closely related, and they are inversely proportional to each other. As the hit rate increases, the miss rate decreases, and vice versa. Therefore, the goal of a cache system is to maximize the hit rate and minimize the miss rate, which can be achieved by using cache algorithms that prioritize frequently accessed data, maintaining a larger cache size, and reducing the cache access latency.
Memory Mapping Techniques
Direct Mapping
Direct mapping is a common technique used in computer memory organization to map memory addresses to specific locations in a cache or main memory.
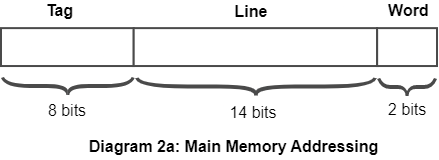
In direct mapping, each memory location in the cache or main memory is assigned a unique identifier or tag. When the CPU accesses a memory location, the memory controller uses a specific function to calculate the cache line or memory block that the location maps to, based on the memory address and a predetermined cache or memory block size.
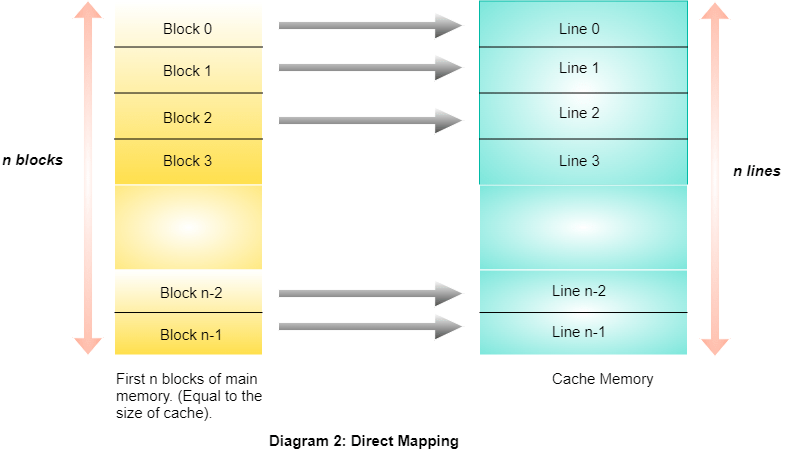
In direct mapping, each memory location in the main memory is mapped to a single cache line, which means that only one cache line can hold the contents of that memory location. This is in contrast to other mapping techniques, such as associative mapping or set-associative mapping, which allow a memory location to be mapped to multiple cache lines.
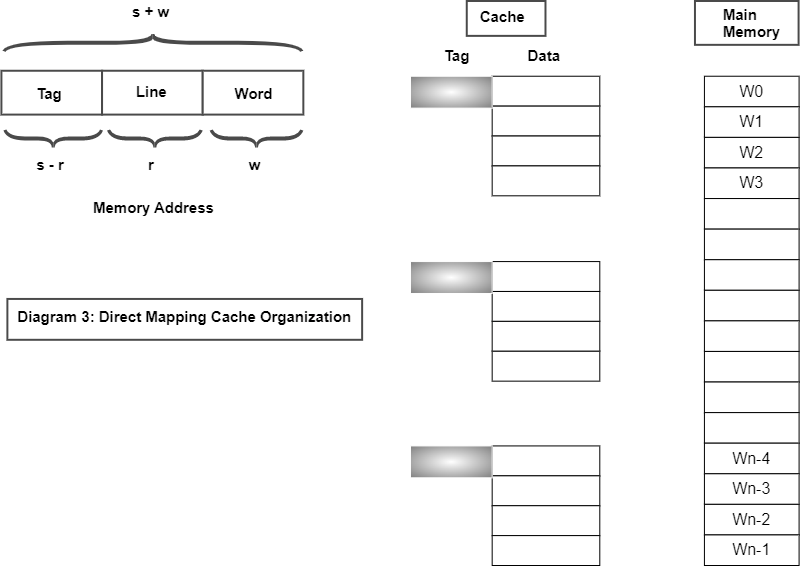
Direct mapping has some advantages, including its simplicity and low hardware cost, since only a small amount of hardware is required to implement the mapping function.
However, direct mapping also has some limitations.
One limitation is that if two memory locations map to the same cache line, they will cause a cache conflict, which means that the cache must evict one of the memory locations from the cache, even if they are accessed at different times. This can cause performance issues if the conflicting memory locations are frequently accessed by the CPU.
Direct mapping is commonly used in the design of CPU caches and main memory, and is often combined with other techniques, such as prefetching and write-back or write-through policies, to optimize the performance of the memory system.
Associative Mapping
Associative mapping is a technique used in computer memory organization to map memory addresses to specific locations in a cache or main memory. Unlike direct mapping, which assigns a unique identifier or tag to each memory location, associative mapping allows a memory location to be mapped to multiple cache lines or memory blocks.
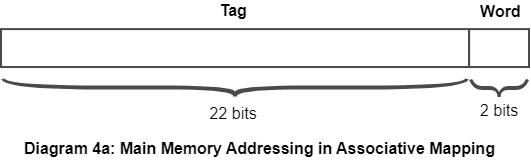
In associative mapping, the cache or main memory is organized as a set of entries, each of which contains a tag, a data field, and a valid bit. The tag is used to identify the memory location that the entry corresponds to, and the data field contains the contents of that memory location. The valid bit indicates whether the entry is currently storing valid data.
When the CPU accesses a memory location, the memory controller searches the cache or main memory for an entry with a matching tag. If a match is found, the memory controller retrieves the data from the cache or main memory and returns it to the CPU. If no match is found, the memory controller selects an available entry and stores the tag and data of the memory location in that entry.
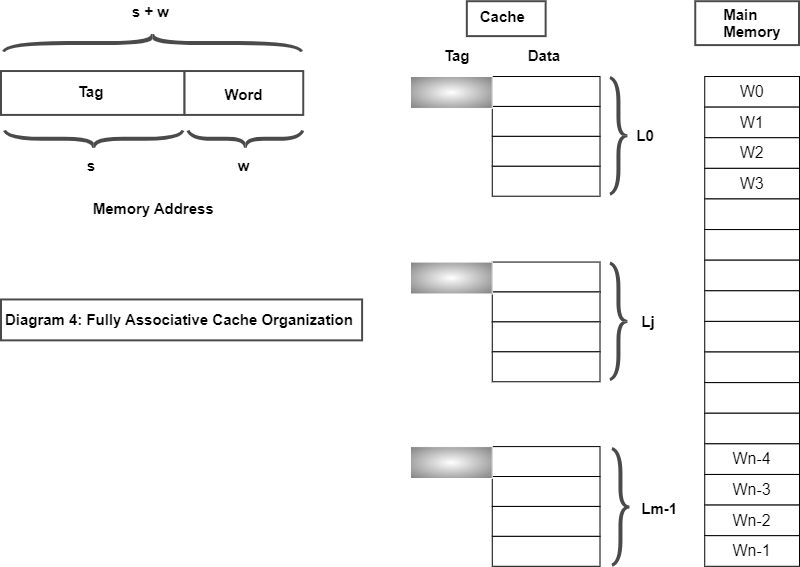
One advantage of associative mapping is that it eliminates the cache conflicts that can occur in direct mapping, since multiple memory locations can be stored in the same cache set. This reduces the likelihood of cache misses and can improve the performance of the memory system.
However, associative mapping is more complex and requires more hardware than direct mapping, since it must perform a search for a matching tag each time the CPU accesses a memory location.
Set-associative mapping is a hybrid approach that combines the advantages of direct mapping and associative mapping, by dividing the cache into a set of smaller direct-mapped sub-caches. Each sub-cache can store a limited number of memory locations, and each memory location can be mapped to a specific sub-cache using direct mapping. This allows multiple memory locations to be stored in the same sub-cache, providing some of the benefits of associative mapping, while still maintaining the simplicity and efficiency of direct mapping.
Set Associative Mapping
Set-associative mapping is a hybrid technique used in computer memory organization to map memory addresses to specific locations in a cache.
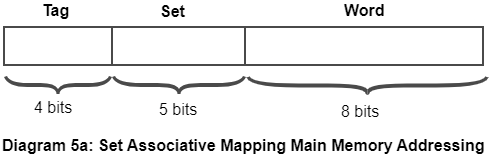
Set-associative mapping combines the advantages of direct mapping and associative mapping, by dividing the cache into a set of smaller direct-mapped sub-caches. Each sub-cache is typically organized as a two-level hierarchy, with a set of cache lines, and each cache line containing a tag and a data field.
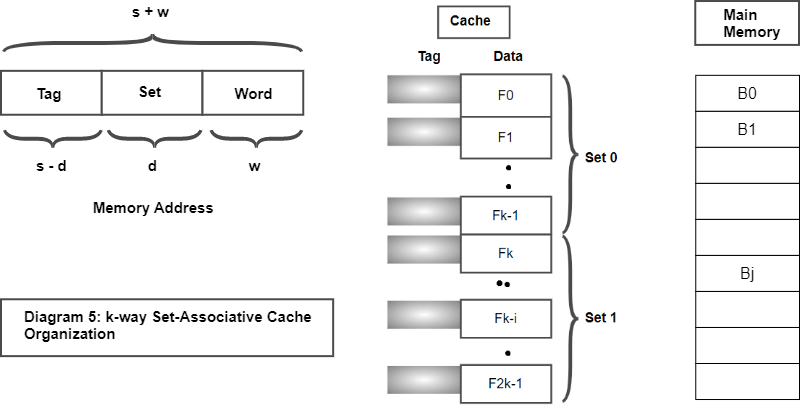
The cache lines within each sub-cache are mapped using direct mapping, which means that each memory location is mapped to a specific cache line within a specific sub-cache. However, multiple memory locations can be stored in the same sub-cache, providing some of the benefits of associative mapping.
The number of cache lines in each sub-cache is typically limited, and the cache lines are organized into sets, each of which contains a fixed number of cache lines. The number of sets is typically a power of 2, and the size of each set is usually smaller than the total number of cache lines in the cache.
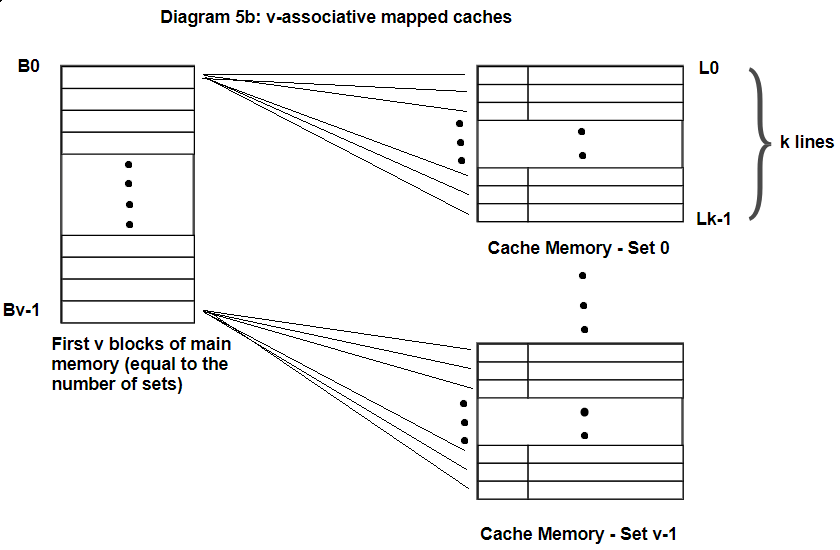
When the CPU accesses a memory location, the memory controller first determines which sub-cache the memory location is mapped to using direct mapping. Within the selected sub-cache, the memory controller searches for a cache line with a matching tag. If a match is found, the memory controller retrieves the data from the cache line and returns it to the CPU. If no match is found, the memory controller selects an available cache line within the same set, evicting the least recently used cache line if necessary, and stores the tag and data of the memory location in that cache line.
Set-associative mapping provides a balance between the simplicity and efficiency of direct mapping, and the flexibility and performance of associative mapping. It reduces the likelihood of cache conflicts, which can occur in direct mapping, while still maintaining the simplicity and efficiency of direct mapping. Set-associative mapping is commonly used in modern CPU cache designs, where the size and complexity of the cache hierarchy can have a significant impact on the overall performance of the CPU.
Replacement Algorithms
In computer cache, a replacement algorithm is used to select which cache line to evict when the cache is full and a new memory block needs to be brought into the cache. There are several different replacement algorithms that can be used, each with its own strengths and weaknesses.
The most commonly used replacement algorithms are:
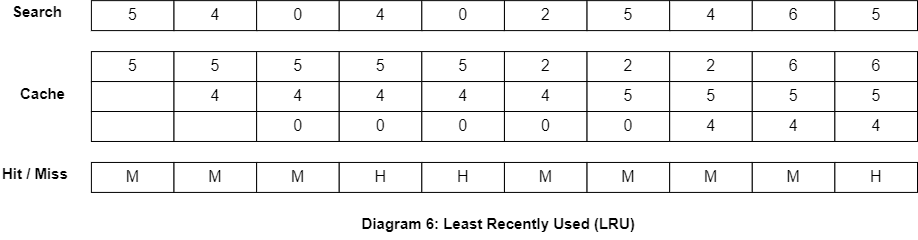
Least Recently Used (LRU)
LRU is a widely used replacement algorithm that evicts the least recently used cache line. This algorithm works by maintaining a list of cache lines in order of their usage, with the most recently used cache lines at the front of the list and the least recently used cache lines at the end of the list. When a new memory block needs to be brought into the cache, the cache controller evicts the cache line at the end of the list.
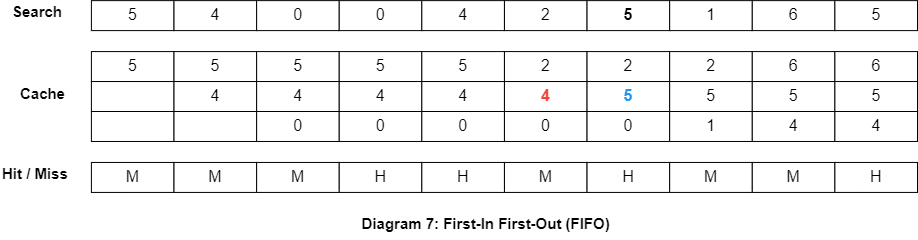
First-In, First-Out (FIFO)
FIFO is a simple replacement algorithm that evicts the cache line that was brought into the cache first. This algorithm works by maintaining a queue of cache lines in the order that they were brought into the cache. When a new memory block needs to be brought into the cache, the cache controller evicts the cache line at the front of the queue.
Least-Frequently Used (LFU)
LFU is a replacement algorithm that evicts the cache line that has been used the least number of times. This algorithm works by maintaining a counter for each cache line that is incremented each time the cache line is accessed. When a new memory block needs to be brought into the cache, the cache controller evicts the cache line with the lowest counter.
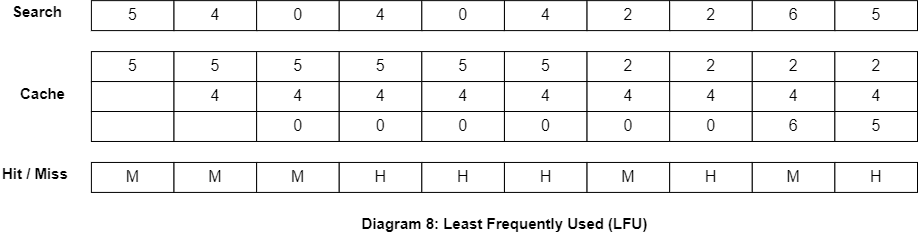
Most Recently Used (MRU)
MRU is a replacement algorithm that evicts the most recently used cache line. This algorithm works by maintaining a list of cache lines in order of their usage, with the most recently used cache lines at the end of the list and the least recently used cache lines at the front of the list. When a new memory block needs to be brought into the cache, the cache controller evicts the cache line at the end of the list.
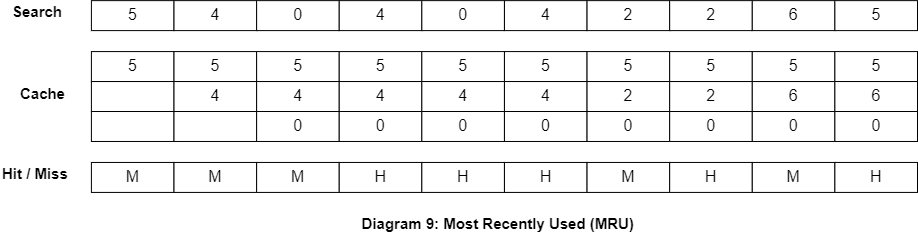
Each of these replacement algorithms has its own strengths and weaknesses, and the choice of algorithm depends on the specific requirements of the cache and the performance characteristics of the system.
- LRU is generally considered to be a good all-around replacement algorithm, while LFU is more suited for systems with a high degree of temporal locality.
- FIFO and MRU are simpler algorithms that may be appropriate for systems with limited hardware resources.
Sequential vs. Random Access
Sequential access and random access are two different ways of accessing data in a computer system.
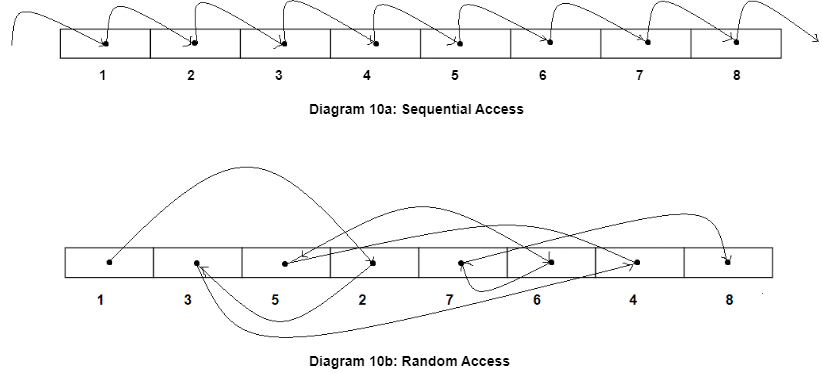
Sequential access involves accessing data in a sequential order, from the beginning to the end of the data. In this mode of access, the data is stored in a continuous sequence and is accessed one after the other. For example, if you have a text file, reading the file from start to end is a sequential access. The advantage of sequential access is that it is easy to implement and requires less memory, but it can be slow for accessing specific pieces of data in large datasets.
Random access, on the other hand, involves accessing data in a non-sequential order, where the data can be accessed directly by its position or address in memory. In this mode of access, the data is stored in a non-continuous manner and can be accessed randomly. For example, accessing an element in an array by its index is a random access. The advantage of random access is that it allows for faster access to specific pieces of data, but it may require more memory for storing additional metadata, such as indexes or pointers.
In general, sequential access is best suited for situations where data is accessed in a linear order, such as reading from files or streaming data. Random access is best suited for situations where data is accessed in a non-linear order, such as searching, sorting, or accessing individual elements in a dataset.
In summary, sequential access and random access are two different modes of accessing data in a computer system, with sequential access accessing data in a linear order, and random access accessing data in a non-linear order. The choice of access method depends on the nature of the data and the type of operation being performed.
Read-Write Policy
In a computer system, a cache is a small amount of fast memory that stores frequently accessed data, in order to speed up the overall performance of the system.
A cache can be organized in different ways, but in general, a cache memory consists of a set of cache lines or blocks, where each line contains a portion of the data from main memory. When the processor needs to access a memory location, the cache controller first checks whether the requested data is present in the cache. If it is, the data can be accessed from the cache quickly, without accessing the slower main memory.
One important aspect of cache design is the read-write policy, which determines how the cache handles read and write operations.
In a write-through cache policy, every write operation updates both the cache and the main memory simultaneously. This ensures that the data in the cache is always up-to-date with the data in the main memory. However, this policy can result in a significant amount of write traffic to the main memory, which can be slow, and can also reduce the overall performance of the system.
In a write-back cache policy, write operations update only the cache, and the modified data is written back to the main memory only when the cache block is replaced. This can result in fewer write operations to the main memory, which can improve the overall performance of the system. However, it also introduces the possibility of data inconsistencies if the modified data is not written back to the main memory in a timely manner.
In summary, the read-write policy in a cache determines how read and write operations are handled by the cache, and can significantly affect the performance and consistency of the system.
Impact of Cache on Performance
The cache is an important component of a computer system that can have a significant impact on system performance. Here are some ways in which the cache affects performance:
01
Faster Access to Data
The primary benefit of a cache is that it allows for faster access to data. Because the cache is faster than main memory, accessing data from the cache can be much quicker than accessing data from main memory. This can result in faster program execution and improved system responsiveness.
02
Reduced Memory Traffic
When data is frequently accessed, it can be stored in the cache, reducing the number of requests to main memory. This can reduce memory traffic and improve system performance.
03
Lower Latency
Because the cache is located closer to the processor than main memory, the time it takes to access data from the cache is lower than the time it takes to access data from main memory. This lower latency can improve system performance by reducing the time it takes for the processor to access data.
04
Increased Hit Rate
The hit rate of a cache refers to the percentage of memory requests that are satisfied by the cache. A high hit rate means that a large number of requests are satisfied by the cache, which can reduce the number of requests to main memory and improve system performance.
05
Increased Power Consumption
While the cache can improve system performance, it also consumes power. The larger the cache, the more power it consumes. This can be an issue in battery-powered devices, where minimizing power consumption is important.
In summary, the cache can have a significant impact on system performance by reducing memory traffic, improving latency, and increasing hit rate. However, the size of the cache and the tradeoff between performance and power consumption must be carefully considered in system design.
Importance of Understanding Locality in Coding
Consider the below two-dimensional array.
Suppose we want to calculate the sum of elements in the array. Now, refer to the below versions of doing it.
Good Locality
sum = 0
for (i=0; i < num_of_rows; i++)
for (j=0; j < num_of_cols; j++)
sum = sum + A[i][j]
printf(“Sum of the elements in the array = ”, sum);

Since we move in the row-major format, we find that the code exhibits good spatial locality (every next element fetched from the array is co-located).
Bad Locality
sum = 0
for (i=0; i < num_of_rows; i++)
for (j=0; j < num_of_cols; j++)
sum = sum + A[j][i]
printf(“Sum of the elements in the array = ”, sum);
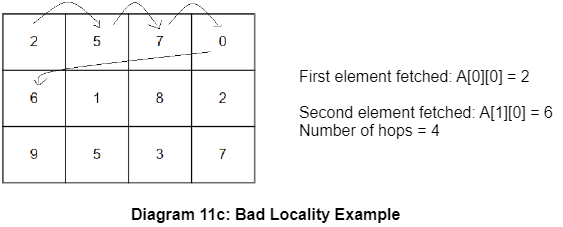
Here, the traversal happens vertically. Since the storage moves horizontally, the system will have to search among all elements that lie between the current element and the value to be found next. This takes more time and this code is said to have bad locality.
From the above two versions, we can see that while the sum value will be the same, the time taken by the code with the bad locality will be more than the one with good locality.
How to Write Cache-friendly Code?
Writing cache-friendly code is important for optimizing performance in computer systems. Here are some tips to help you write cache-friendly code:
Use Contiguous Data Structures from Memory
Use data structures that are contiguous in memory: Data that is contiguous in memory is more likely to be stored together in the cache, which can improve cache hit rates. Arrays and structs are examples of contiguous data structures.
Access Memory Sequentially
Access memory in a sequential manner: Accessing memory in a sequential manner, such as iterating through an array or a linked list, can improve cache performance by increasing spatial locality. This means that nearby data is more likely to be stored together in the cache.
Avoid Pointer Chasing
Pointer chasing, where a program accesses memory via pointers that point to other memory locations, can result in poor cache performance. Instead, consider using arrays or other data structures that allow for direct access to memory.
USE DATA STRUCTURES WITH A SMALL MEMORY FOOTPRINT
Smaller data structures, such as bit fields or bitmaps, can improve cache performance by fitting more data into the cache.
MINIMIZE CACHE MISSES
Cache misses occur when the requested data is not present in the cache, and can significantly impact performance. To minimize cache misses, try to predict which data will be needed next and prefetch it into the cache.
USE DATA-ORIENTED DESIGN
Data-oriented design is an approach to software design that focuses on organizing data for efficient processing. By organizing data in a cache-friendly manner, you can improve cache performance and overall system performance.
In summary, writing cache-friendly code involves using contiguous data structures, accessing memory in a sequential manner, minimizing pointer chasing, using small data structures, minimizing cache misses, and using data-oriented design. By following these tips, you can optimize the performance of your code and improve overall system performance.
I hope that this post has given you a better understanding of how the cache performs as an integral part of today’s digital systems.
References:
1) Stallings, William (2016). Computer Organization and Architecture (Tenth Edition). Pearson.